How relative novices make sense of code coverage and mutation-based feedback
This is an overview of the research paper A Model of How Students Engineer Test Cases with Feedback published in ACM Transactions on Computing Education. The work was conducted at Cal Poly and was led by MS student Austin Shin.
Background
Most programming courses require students to write automated software tests to verify and demonstrate the correctness of their solutions to programming problems. The quality of these test suites can vary in terms of their defect-detection capability. The thoroughness of a test suite can be measured using a test adequacy criterion like code coverage or mutation analysis.
In most CS courses, it is matter of course to assess both the correctness of students’ programmed solutions as well as the thoroughness of their software tests. As students are encouraged to frequently write and run their own tests to check the correctness of their programs, so they are encouraged to frequently assess the thoroughness of their tests using one of the above criteria.
Within this context, it is useful to understand how students respond to software testing feedback while creating test suites.
Summary
We qualitatively studied how students made sense of software testing feedback generated using two feedback mechanisms: code coverage and mutation analysis.
Our findings are summarised in the process model below.
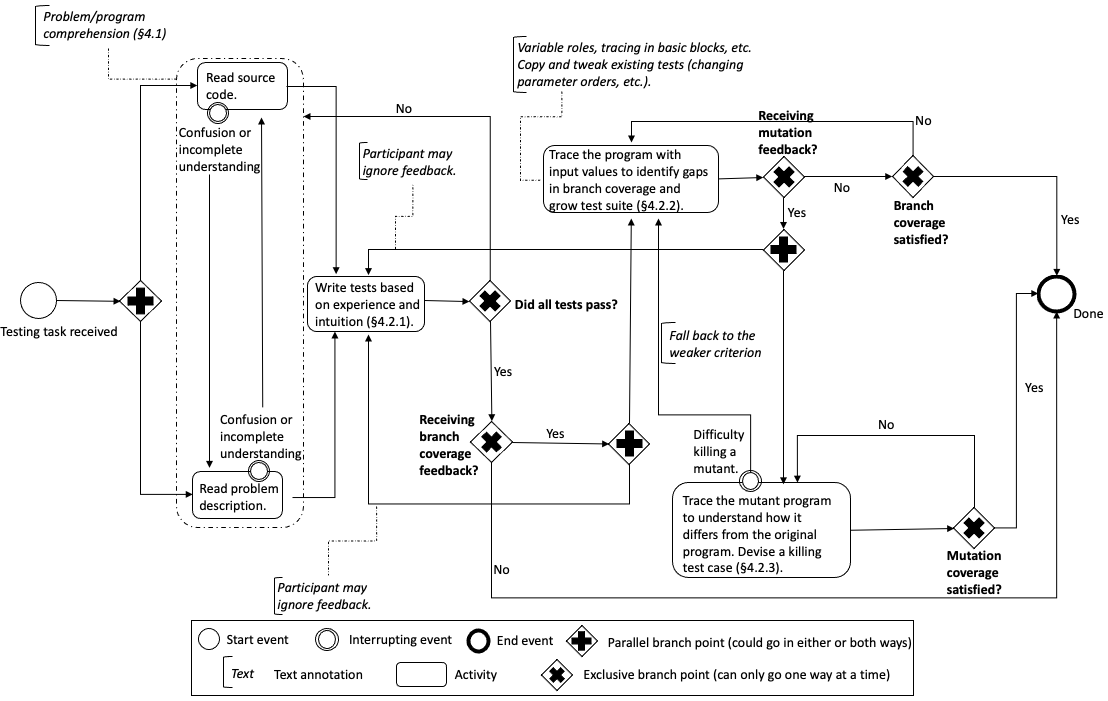
Method
We did a series of one-on-one interviews in which we gave students a number of small programs for which they were asked to write test cases. Students were asked to think out loud while performing the testing tasks, and the sessions were recorded.
Interviews went roughly as follows:
- Warm-up problem, with no testing feedback
- First testing problem, with no testing feedback
- Warm-up problem, with code coverage feedback
- Second testing problem, with code coverage feedback
- Warm-up problem, with mutation-based feedback
- Third testing problem, with mutation-based feedback
Below is the interface in which students were given testing exercises.
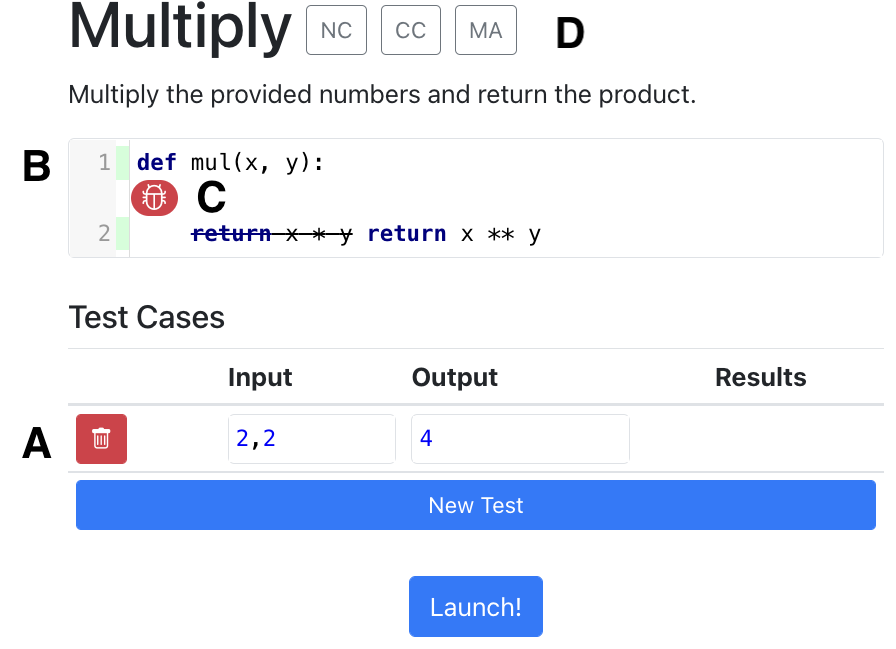
return x * y was mutated to return x ** y. The interviewer used the toggles at the top of the screen to switch between no coverage, code coverage, or mutation-based feedback, based on the experimental condition (D).We qualitatively analysed the transcripts from these interviews. For details about our analytic method, see the paper.
Results
Here are the highlights:
Problem and program comprehension had a strong influence on students’ abilities to write useful tests. If they had a shaky understanding of the problem or the code under test, their ability to address gaps in code coverage or mutation coverage suffered.
Various intuitions came into play when no feedback was available. Nearly all students started with a “happy path” test case—something simple that they could quickly work out in their minds. They may have been using these simple test cases as scaffolds to confirm that they understood the problem and program correctly.
When no testing feedback was available, students often chose test inputs based on intuitions about “edge cases”—these most often took the form of boundary values for the data type at hand (e.g., zero, negative numbers, or empty lists). Importantly, these types of inputs were chosen whether or not they represented unexplored equivalence partitions in the input space.
Some students started by identifying beacons1 in the problem description or program, and targeting their initial tests toward those beacons. For example, in the Rainfall problem, the program is given an input list of numbers (daily rainfall), and is expected to compute the mean of all the positive numbers that occur before a “sentinel value” (say, 99999). In our interviews, most students zeroed in on that sentinel value requirement and wrote an early test to target that requirement.
Finally, because students had seen code coverage before, some of them mentally simulated code coverage to self-assess their own test suites and identify gaps.
Code tracing strategies were employed while addressing code coverage feedback. As described above, code comprehension played an important role in students’ abilities to address coverage gaps. They used various strategies to manage the cognitive load of code comprehension involved during testing. For example,
- While tracing code to identify gaps in (code or mutation) coverage, students often limited their tracing to the basic block2 in which the gap existed.
- They used variable roles3 to help them reason about the variables involved their tracing.
- Sometimes, they simply ignored the feedback and opted to write tests based on their intuitions.
Addressing mutation-based feedback proved to be cognitively demanding. Reasoning about mutation-based feedback appeared to be a high-cognitive-load activity for the interviewed students. To devise test cases to address a gap in mutation coverage, students needed to develop and maintain an understanding of the mutated program while simultaneously maintaining their understanding of the original program. Moreover, they need to identify to point at which the two programs diverge. This was a demanding task.
Even after demonstrating an understanding of the idea behind mutation analysis, students struggled mightily on certain mutants. One student was so distracted by this parallel comprehension task that when they eventually wrote a test case, they wrote one that would pass the mutated program, and fail the original program (i.e., the opposite of the task at hand).
Difficulties more commonly arose for mutants that appeared at conditional branching points in the program, as opposed to, say, mutants that involved changes to arithmetic expressions or variable assignments.
As before, students developing strategies to manage this demanding parallel code tracing task:
- Like with code coverage, they traced basic blocks and reasoned about the program in terms of variable roles.
- When addressing mutation-based feedback was too difficult, they “fell back” to addressing the weaker criterion (code coverage) instead. This heuristic—of simply targeting code coverage instead of mutants—was sometimes fruitful.
- Finally, some students ignored the specific mutations and focused only on the fact that they were present. The presence of an un-addressed mutant alerted students to “suspicious” lines of code, and they did not need to look at the specific mutation in order to target their testing toward those lines.
For more details, see the paper.
-
Prominent structures or symbols (variable names, function names, comments) in a program (or problem description, here) that help a reader to quickly understand the program’s purpose. ↩
-
A basic block in a program is a straight-line sequence of statements such that “if the first statement is executed, all statements in the block will be executed”. ↩
-
Sajaniemi suggests that a small number of categories can describe the purposes of most variables in most programs. When novice programmers were explicitly taught to recognise these categories, their performance on code comprehension tasks improved significantly. This general idea has a strong basis in human cognition, even if the specific categories suggested are are bit limited to imperative programming languages. ↩